Конфиденциальность — не опция
Большинство сервисов транскрибации отправляют ваш файл на облачные серверы OpenAI, Google или Microsoft. Это неприемлемо для интервью, переговоров, юридических записей и любых материалов под NDA.
Облачные сервисы
- ✖ Файл загружается на серверы OpenAI / Google / AWS.
- ✖ Данные могут использоваться для обучения моделей.
- ✖ Нарушение 152-ФЗ при работе с персональными данными.
- ✖ Запрещено в корпоративных и государственных контурах.
LexiMedia AI
- ✔ Обработка только на локальном сервере — никаких внешних API.
- ✔ Исходные файлы удаляются сразу после сдачи работы.
- ✔ Подходит для юристов, психологов, NDA-материалов.
- ✔ Работает без подключения к интернету на стороне обработки.
Как сделать заказ
Всё через Telegram — никаких регистраций и форм.
/start или просто опишите задачу. Принимаются файлы до 2 ГБ: mp4, mp3, wav, webm, m4a и другие форматы.
Что умеет система
Разделение по спикерам
Автоматическая идентификация голосов. До 10 участников в одной записи. Итог — реплики подписаны именами, а не «Спикер 1».
Точные таймкоды
Каждая реплика привязана к временной метке с точностью до слова. DOCX содержит таймкоды — легко найти любой момент в записи.
Форматы экспорта
DOCX — официальный протокол с форматированием. SRT — субтитры для видео. TXT — в базу знаний. MP3 — аудио из видео.
Шум и плохое качество
Работаем с записями из Zoom/Teams (эхо, артефакты сжатия), диктофонов, телефонных переговоров и полевых интервью.
Приём по ссылке
Можно прислать ссылку на YouTube, VK Видео или другой хостинг — скачаем и обработаем. Не нужно самостоятельно скачивать и пересылать тяжёлые файлы.
Русский и другие языки
Основная специализация — русский. Также поддерживаются английский и большинство европейских языков через мультиязычную модель Whisper.
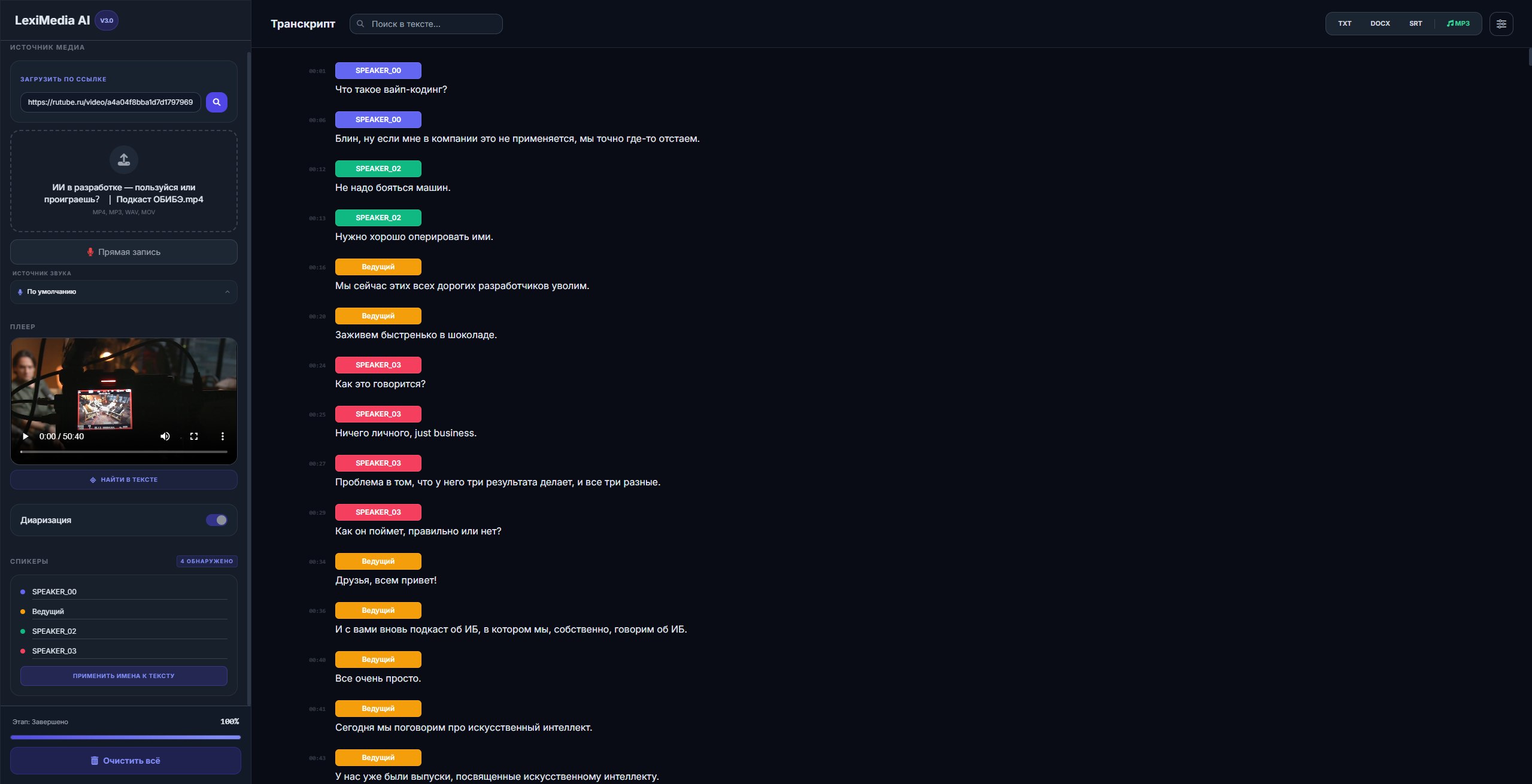
Система в работе
Реальный результат: подкаст с 4 спикерами, загруженный по ссылке с Rutube. Система автоматически определила голоса, разметила реплики цветом и привязала к таймкодам.
Доставка результата
Вы получаете готовый файл до оплаты — и можете убедиться, что работа выполнена.
Почему качество выше облачного
В основе системы — открытый конвейер WhisperX с максимальной моделью large-v3, которую облачные сервисы используют только на платных тарифах. Здесь это стандарт для каждого заказа.
Whisper Large-v3
Лучшая публичная модель распознавания речи от OpenAI. Запускается локально — без ограничений по объёму и без очередей.
GPU-ускорение
Обработка на NVIDIA RTX с CUDA. Скорость транскрибации в 4–6 раз быстрее реального времени — час записи готов за 10–15 минут.
Диаризация голосов
Нейросетевая идентификация каждого спикера на уровне фонем. Результат — «Александр сказал...», а не «SPEAKER_00 сказал...».